2026년 5월 OWASP Seoul에서 AI기반 취약점 탐지 워크플로우 구축기를 주제로 발표했다. 반년 동안 직접 만들고 돌리면서 워크플로우를 어떻게 구성했는지, 그리고 한계가 어디였는지를 담은 내용이다.
시작은 "진짜 0-day를 찾을 수 있을까"였다
처음에는 반신반의했다. 실제 운영 중인 오픈소스에서 벤더가 인정할 만한 0-day를 AI로 찾을 수 있을지는 전혀 다른 문제라고 생각했다.
그런데 지난 1년의 흐름을 보면 분위기가 확실히 달라지고 있었다. MCP가 나오면서 모델이 외부 도구를 호출하는 방식이 정리되기 시작했고, XBOW 같은 AI 펜테스터가 버그바운티 플랫폼에서 눈에 띄는 성과를 냈다. AIxCC처럼 AI가 취약점을 찾고 패치까지 만드는 대회도 열렸고, Claude Code, Cursor, Codex 같은 에이전트 기반 CLI 도구도 개발자들이 일상적으로 쓰는 도구가 됐다.
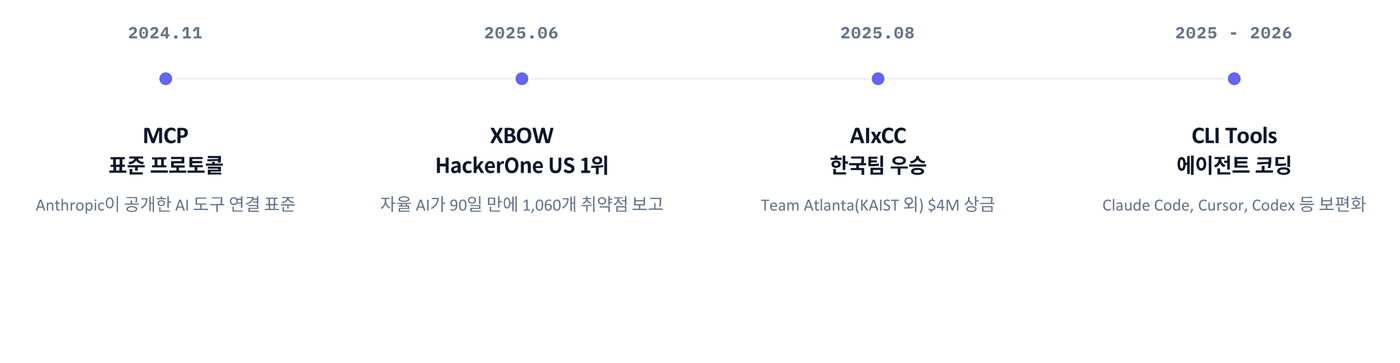
이 흐름을 보면서 "나도 AI로 취약점을 찾아봐야겠다"는 생각이 들었다. 다만 그냥 레포지토리를 열고 "취약점 찾아줘"라고 시키는 방식으로는 오래 못 갈 것 같았다. 같은 도구를 쓰는 사람은 계속 늘어날 테고, 차이는 결국 어떤 방법론으로 AI를 활용하느냐에서 날 수밖에 없다고 봤다.
반년 동안 나온 결과
먼저 숫자부터 정리하면 이렇다.

발표 시점에 CVE가 부여된 건은 17건이었다. 49건은 CVE를 포함해 버그바운티 플랫폼이나 벤더 검증 과정에서 보안 이슈로 인정된 건을 모두 합산한 숫자다.
찾은 취약점의 전체 목록은 여기에서 볼 수 있다.
발표 시점 기준으로 HackerOne Korea Reputation #1도 기록했다.
가장 임팩트가 컸던 사례는 Grafana의 권한 상승(Privilege Escalation) 취약점이었다. Grafana는 대시보드별로 권한을 나눠 설정할 수 있다. 예를 들어 어떤 사용자는 특정 대시보드 하나에만 관리자 권한을 갖고, 다른 대시보드에는 접근하지 못하게 만들 수 있다.
문제는 권한 관리 API 쪽에서 "내가 권한을 가진 대시보드"와 "수정하려는 대상 대시보드"의 범위가 제대로 맞물리지 않았다는 점이었다. 사용자가 한 대시보드에 대한 관리자 권한만 가지고 있어도, 다른 대시보드의 권한 정보를 읽거나 수정할 수 있는 흐름이 생겼다.
공격자에게 필요한 권한도 높지 않았다. 특정 대시보드 하나에 대한 관리자 권한만 있으면 공격 조건이 성립했고, 원래 접근 권한이 없는 대시보드에 자기 자신을 Admin으로 추가하는 것도 가능했다. CVSS는 8.1이었다.
내가 만든 워크플로우
구조는 결국 세 단계로 수렴했다
여러 버전의 워크플로우를 만들고 버리면서, 결국 세 단계로 수렴했다. 분석 대상 전처리, 취약점 가설 생성, 취약점 검증이다.

단순해 보이지만 각 단계의 책임을 얼마나 분명히 나누느냐에 따라 결과가 많이 달랐다. 전처리 단계에서는 입력을 뒤 단계가 쓰기 좋은 형태로 가공해야 한다. 후보 탐지 단계에서 검증까지 욕심내면 후보가 줄어드는 대신 좋은 후보도 같이 사라진다. 검증 단계가 약하면 오탐이 쌓여서 사람이 검증할 수 없는 양이 된다.
모델을 섞어 쓴 이유
당시에는 GLM 4.7, GLM 5.1, GPT 5.4를 사용했다. 대략 이 순서로 성능이 좋고 가격도 비쌌다.
처음부터 가장 강한 모델만 쓰면 구조는 단순해진다. 문제는 비용이다. 큰 오픈소스 레포 하나를 분석하면 청크가 수십 개에서 수백 개까지 나온다. 각 청크마다 여러 번 호출하면 한 레포에 수백에서 수천 번의 LLM 호출이 들어간다. 모든 단계에 가장 비싼 모델을 쓰면 금방 감당하기 어려워진다.
그래서 내 워크플로우에서는 단계마다 필요한 역할에 맞춰 모델을 다르게 썼다. 호출 수가 많은 단계에서는 비용을 더 신경 쓰고, 판단 품질이 중요한 단계에서는 더 강한 모델을 쓰는 식이었다.
아래부터는 실제로 사용했던 워크플로우를 단계별로 풀어보겠다.
1단계: 분석 대상 전처리
레포지토리 전체를 LLM 컨텍스트에 그대로 넣을 수는 없다. 코드 양도 많고, 한 번에 너무 많은 파일을 보면 모델이 중요한 흐름을 놓치기 쉽다.
그래서 코드베이스를 파일 크기 기준으로 청크로 나눴다.
청크를 너무 크게 만들면 뒤 단계에서 세부 로직을 놓치기 쉽고, 너무 작게 만들면 호출 수가 폭증한다. 이 단계에서는 취약점을 판단하지 않고, 뒤 단계가 분석할 수 있는 적당한 크기의 입력 단위를 만드는 데 집중했다.

2단계: 취약점 가설 생성
전처리된 각 청크를 LLM에게 보내 잠재 취약점 후보를 넓게 뽑았다. 이 단계에서는 정확도보다 누락을 줄이는 것을 더 중요하게 봤다. 나중에 걸러낼 수는 있지만, 처음부터 놓친 후보는 되살리기 어렵기 때문이다.
여기서는 검증을 거의 시키지 않았다. "이게 진짜 취약점인지 결론내라"가 아니라 "공격 가능성이 있는 지점을 최대한 찾아라"에 가깝게 역할을 줬다. 권한 검증 누락, IDOR, 입력 처리 실수, 비즈니스 로직 불일치 같은 후보를 넓게 모으는 단계였다.
이 단계에서는 GLM 4.7을 사용했다. GLM 5.1보다 성능은 낮지만 가격이 훨씬 저렴했고, 실제로 많은 취약점 후보는 처음부터 깊은 추론을 요구하지 않았다. 이 단계에서는 아주 어려운 판단을 한 번 잘하는 것보다, 많은 청크를 빠르게 훑으면서 의심 지점을 놓치지 않는 쪽이 더 중요했다.

3단계: 취약점 검증
가장 많이 고친 부분이 검증 단계였다. 후보 탐지 단계에서 나온 결과에는 오탐이 정말 많았다. 코드 일부만 보면 취약점처럼 보이지만 실제로는 공격자 조건이 성립하지 않거나, 상위 레이어에서 막히거나, 영향도가 보안 이슈라고 보기 애매한 경우가 많았다.
그래서 검증을 두 단계로 나눴다. GLM 5.1로 명백한 오탐을 먼저 제거하고, 거기서 살아남은 것만 GPT 5.4로 다시 보는 방식이다. GPT 5.4를 모든 후보에 쓰지 않아도 되고, 마지막에 남는 건 두 번의 검증을 통과한 것들뿐이다.

이 단계를 지나도 마지막에는 사람이 직접 재현하고 판단해야 했다.
AI 취약점 탐지의 한계
반년 동안 돌려보면서 느낀 한계는 크게 세 가지였다.
개인 버그헌팅 관점에서는 아직 비싸다
큰 오픈소스 레포 하나를 분석하면 수십 개에서 수백 개의 청크가 나온다. 여기에 청크당 여러 번의 LLM 호출을 곱하면 한 레포 분석에 수백에서 수천 번의 호출이 들어간다.
문제는 버그바운티 보상이 항상 나오는 게 아니라는 점이다. 한 레포를 분석했을 때 보상은 대부분 0이고, 운이 좋으면 몇백에서 천 달러 정도다. 반면 API 토큰 가격 기준으로 계산하면 큰 레포는 수백에서 수천 달러까지 나온다.
내가 이 워크플로우를 돌릴 수 있었던 건 GLM 모델 초기에 덤핑 수준으로 싸게 팔던 시기였기 때문이다. 지금 가격이었으면 못 했을 것 같다. 기업이 자기 코드베이스를 검수하거나 B2B 형태로 스캔 서비스를 운영하는 경우라면 ROI가 나올 수 있지만, 개인 버그헌터 입장에서는 아직 부담이 크다.
취약점의 그레이존
AI는 코드 패턴을 보고 위험도를 판단한다. SSRF, XSS, IDOR, RCE 같은 패턴을 보면 정책 맥락 없이 취약점으로 분류하려는 경향이 있다.
그런데 현실에서는 취약점 여부를 코드가 아니라 정책이 결정하는 경우가 있다.
예를 들어 사용자별 AI 토큰 한도가 있는 SaaS를 생각해보자. 한 사용자가 월간 토큰의 99%를 사용한 상태에서 큰 요청을 보냈고, 서비스가 그 요청을 끝까지 처리해서 결과적으로 한도를 넘겼다.
실제로 GPT는 한도가 초과돼도 진행 중인 요청은 끝까지 처리하는 편이고, Claude는 한도에 도달하면 처리 중간에 바로 멈춘다. AI API를 사용하는 SaaS들도 대부분 비슷하게 마지막 요청은 완료를 보장하는 방식으로 동작한다. 즉, 이 동작이 의도된 정책일 수도 있다는 뜻이다.
코드만 보면 "한도 초과 검증 우회"처럼 보일 수 있다. 하지만 서비스 정책이 "이미 시작된 요청은 완료를 보장한다"라면 의도된 동작이다. 반대로 정책에 명시되어 있지 않다면, 취약점인지 아닌지는 코드만으로는 결론낼 수 없다.
사람은 이런 상황에서 정책 문서를 먼저 찾는다. 문서에 명시되어 있으면 의도된 동작으로 보고, 없으면 팀과 논의한다. LLM은 이런 판단을 내리기 어렵다. 정책 문서가 있어도 이런 세부 동작까지 적혀 있지 않은 경우가 많고, 설령 있어도 "팀에 물어보자"는 결론으로 이어지지 않을 수 있다.
책임 경계 문제
LLM은 보통 하나의 레포지토리를 분석한다. 하지만 실제 서비스는 여러 컴포넌트가 연결되어 동작한다. 분석 중인 레포 밖의 코드는 볼 수 없기 때문에, 보안 처리의 책임이 어느 컴포넌트에 있는지 판단하기 어렵다.
예를 들어 메일 발송 기능이 있는 SaaS를 생각해보자. 구성은 단순하다. SaaS 서비스가 메일 내용을 만들어 발송 요청을 보내고, 메일 서버가 수신자에게 중계하고, 메일 클라이언트가 HTML을 렌더링해서 보여준다. 알림 메일이나 비밀번호 재설정 메일 같은 기능이 모두 이런 구조다.
여기서 SaaS가 사용자 입력을 이스케이프하지 않고 메일 본문에 그대로 넣어 보낸다고 하면, SaaS 코드만 보면 XSS처럼 보인다.
사람은 어떻게 판단할까. 서비스 전체 구조를 같이 살핀다. 실제로 대부분의 메일 클라이언트는 HTML sanitizing을 강하게 하기 때문에, SaaS가 이스케이프를 안 해도 클라이언트 단에서 막힐 가능성이 높다. 그래서 실제 XSS가 성립하지 않는 경우가 많고, 설령 된다 해도 그 책임이 SaaS에 있는지 메일 클라이언트에 있는지가 애매해진다.
LLM은 메일 클라이언트 코드를 볼 수 없어 SaaS 코드만 보고 "이스케이프가 없으니 취약하다"고 결론낼 수 있다. 다른 레포를 추가로 볼 수 있더라도 이스케이프 책임이 어느 쪽에 있는지 결론내기 어렵기 때문에, 결국 취약점으로 검출하는 경우가 생긴다.
세 가지 한계를 얘기했지만, 모두 절대로 극복할 수 없는 한계는 아니다. 다만 AI로 취약점을 분석할 때 자주 마주치는 문제들이고, 특히 정책 판단처럼 사람의 맥락 이해가 필요한 영역은 아직 쉽게 해결되지 않는 부분이라 짚어봤다.
앞으로는
오픈소스 워크플로우는 계속 돌릴 거다. 그러면서 관심은 자연스럽게 다음 단계로 가고 있다. 지금까지는 소스코드가 있는 화이트박스 환경이었다면, 앞으로는 코드 없이 동작하는 블랙박스 앱/웹을 대상으로 한 워크플로우도 만들어보고 싶다. 접근 방식이 어떻게 달라져야 하는지는 직접 만들어보면서 알아갈 생각이다.
개인적으로는 컨퍼런스나 세미나에도 더 자주 나가고 싶다. 발표를 준비하다 보니 평소에 흐릿하게 넘어가던 것들을 다시 정리하게 됐고, 다른 사람들의 발표를 듣는 것도 그만큼 도움이 됐다. 기회가 생기면 계속 해볼 생각이다.
'ai for security' 카테고리의 다른 글
| Building an AI-Based Vulnerability Detection Workflow (0) | 2026.05.27 |
|---|---|
| 2026 ai for security 공부 마일스톤 (1) | 2026.04.01 |
| How I Found Open-Source 0-days with an LLM Multi-Agent Workflow (0) | 2026.02.20 |
| LLM 멀티 에이전트 워크플로우로 오픈소스 제로데이를 찾은 후기 (0) | 2026.02.20 |